The SQA2 Blog: General
The most common method of test case identification is broken, inefficient and often times misses critical cases. These missed test cases can result in bugs and missed deadlines, and negatively impact revenue. To mitigate the risk of missed test cases, organizations seek out and hire highly experienced and costly test case writers. But taking this approach relies almost entirely on the expertise that the test case writer has developed in testing other applications. These test case writers list every happy path, negative and edge case tests they can think of and then stop for a “gut check” regarding whether they’ve missed anything. If their gut response is, “no, I’ve got it all,” they stop there.
As a result of this process, something that should be simple enough to be knocked out by the junior people on the project must be done by either specialists or more experienced team members.
It shouldn’t take a QA Architect to identify test cases
A big problem with this approach to identifying test cases is that even when you hire engineers, including test case writers, who are sufficiently well-versed in software development to be able to “think of everything,” things still come down to a gut check. Which means that, not surprisingly, things still get missed.
If you’d like to take the gut check out of your QA test case identification process and catch more defects, consider switching to the Behavior Based Testing methodology.
BBT simplifies the process
Behavior Based Testing (BBT) offers QA teams an easier, better and more reliable approach for identifying test cases. Because of the simple way that it uses permutations and truth tables to generate test cases, BBT enables you to reliably achieve comprehensive coverage of your application’s requirements.
BBT offers a visual way to map out outcomes, the events that trigger the outcomes, and the inputs needed to make the desired outcomes happen (these are called “contexts” in BBT), and then translate these into Gherkin-style test cases that cover the positive and negative paths, including the edge cases.
With BBT, once something is identified as a requirement and included in a BBT map, you can confidently say that this requirement is quantitatively covered and will be properly tested. Which means that with BBT, your test cases don’t have to be written by highly-experienced QA professionals who have many years of test-case-writing expertise.
A simple example using BBT
For example, say you want to create a way for a new user to sign up for an account.
Using the BBT methodology, the QA engineer would identify the following variables:
- Behavior: user attempts to sign up for an account
- Desired outcome: user account is created
- Context: the inputs that are required to make the outcome happen, such as a valid username, valid email address, valid password, valid address, etc.
- Event: user clicks on the “submit” button to submit the form
Next, the engineer would use these variables to create a visual BBT map focusing on the behavior or function of that particular area of the application:
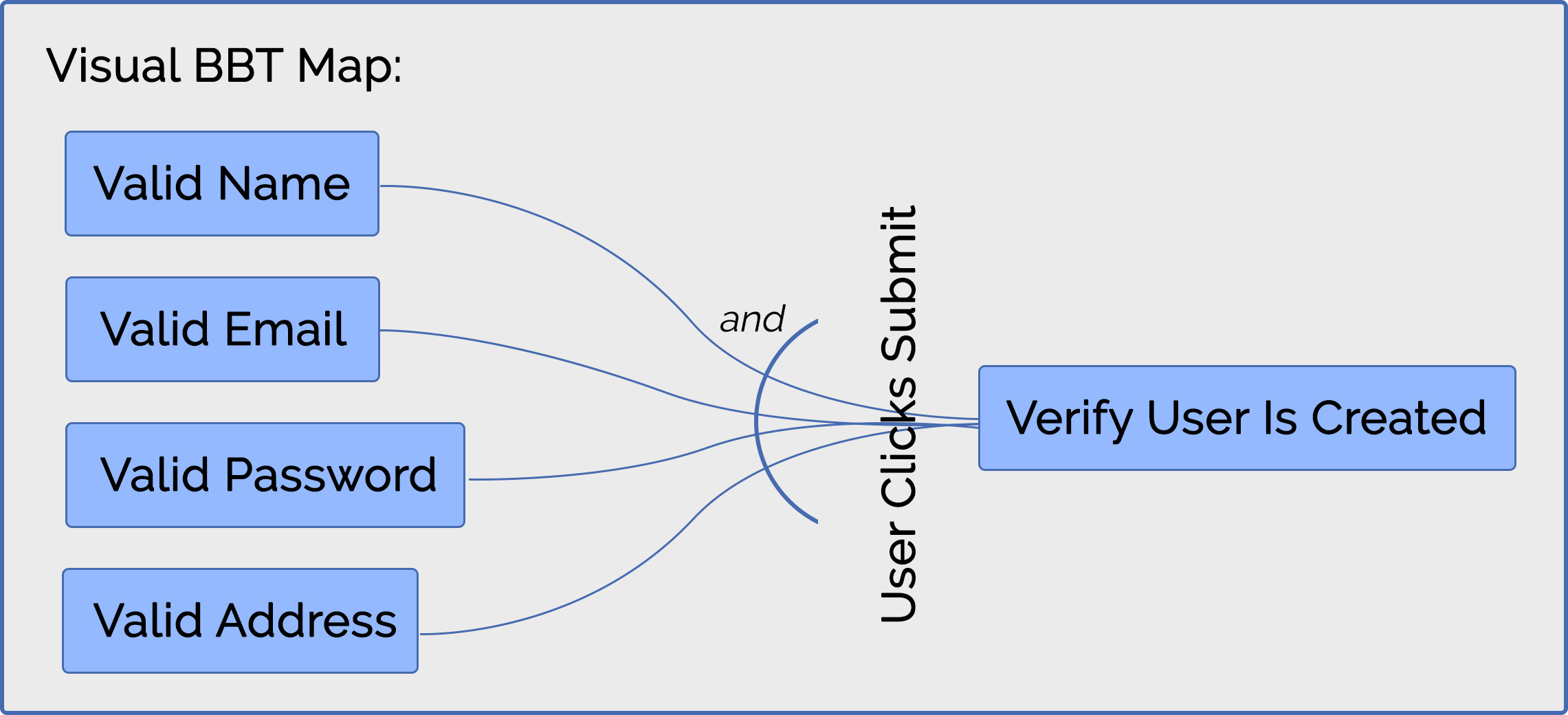
The visual BBT map is then translated into easily-followed Gherkin-style test cases, such as this:

The BBT engine can then be used to automatically and dynamically generate all the related test cases for this visual BBT map, including:
- Positive test cases – The “Happy Path” where all the inputs are valid, you perform an action and the expected outcome happens.
- Negative test cases – The “Not-So-Happy Path” where you provide invalid input and, as a result, fail to achieve the desired outcome. A major benefit to using BBT is that it automatically considers all permutations where each context can be negative.
- Edge case test cases – The “Unpredictable Path,” another type of negative test case, where a random combination of inputs causes an unexpected outcome to happen. Through permutations, the BBT engine identifies all of the possible combinations of positive and negative states of all contexts and writes test cases to cover all of them.
As you can see, the BBT methodology makes it much easier to cover all of your requirements with test cases, even if the test case writer does not have extensive industry expertise.
The beauty of this approach is that once something is identified as a requirement and put into a visual BBT map, you can eliminate the gut check from your test case identification process. With all permutations of test cases being created based on the input provided in the BBT map, you can say with confidence that you have comprehensive coverage for that requirement.
The same example without BBT
In contrast, when using the old, inefficient way of doing things the test case writer sits down and thinks, “I need to test this form. You need to fill in these things, so I’ll write a [static] test case so that when a user fills in their username, email, password and address and then clicks the ‘submit’ button, they’ll get an account.” Then this engineer does a gut check and decides they’re done.

Unfortunately, the engineer may not have considered that there are a whole host of negative and edge cases as well as many possible permutations to address. These are things that BBT gives you without any extra effort or thought.
The bottom line
If your software development QA team is still identifying test cases the old, inefficient and costly way, chances are they are missing test cases that could reveal bugs in your software. BBT provides a methodology and framework for ensuring things don’t get overlooked. You get comprehensive testing coverage for all your app’s identified requirements that is no longer based on a “gut check,” and that enables any test case writer, regardless of experience, to write test cases.